
nunique()를 통해 name열의 데이터 중 고유한 값만 찾아낼 수 있다.
import pandas as pd
colors = pd.read_csv('data/colors.csv')
# name으로 색상 개수 찾기print(colors["name"].nunique())
is_trans 열의 값으로 투명한 색상과 불투명한 색상 개수 찾기
첫번로 groupby()와 count()를 조합할 수 있다.
두번째로는 value_counts()를 사용할 수 있다.
# 투명한 색상 개수print(colors.groupby("is_trans").count())
print(colors["is_trans"].value_counts())
다음으로 아래와 같은 데이터를 찾을 수 있다.
# · 최초의 레고 세트가 출시된 연도와 이 세트의 이름은?print(sets.sort_values('year'))
# · 레고는 운영 첫해에 얼마나 많은 제품을 팔았나?print(sets[sets["year"] == 1949])
# · 부품 수가 가장 많은 상위 5개 레고 세트는?print(sets.sort_values('num_parts', ascending=False).head())
레고의 연도별 세트 수 파악하기
year로 그룹화하고 count()를 사용해서 연도별 출시한 세트 수를 파악할 수 있다.
# 연도를 인덱스, 세트 수를 그 값으로 만들기
sets_by_year = sets.groupby("year").count()
print(sets_by_year["set_num"])
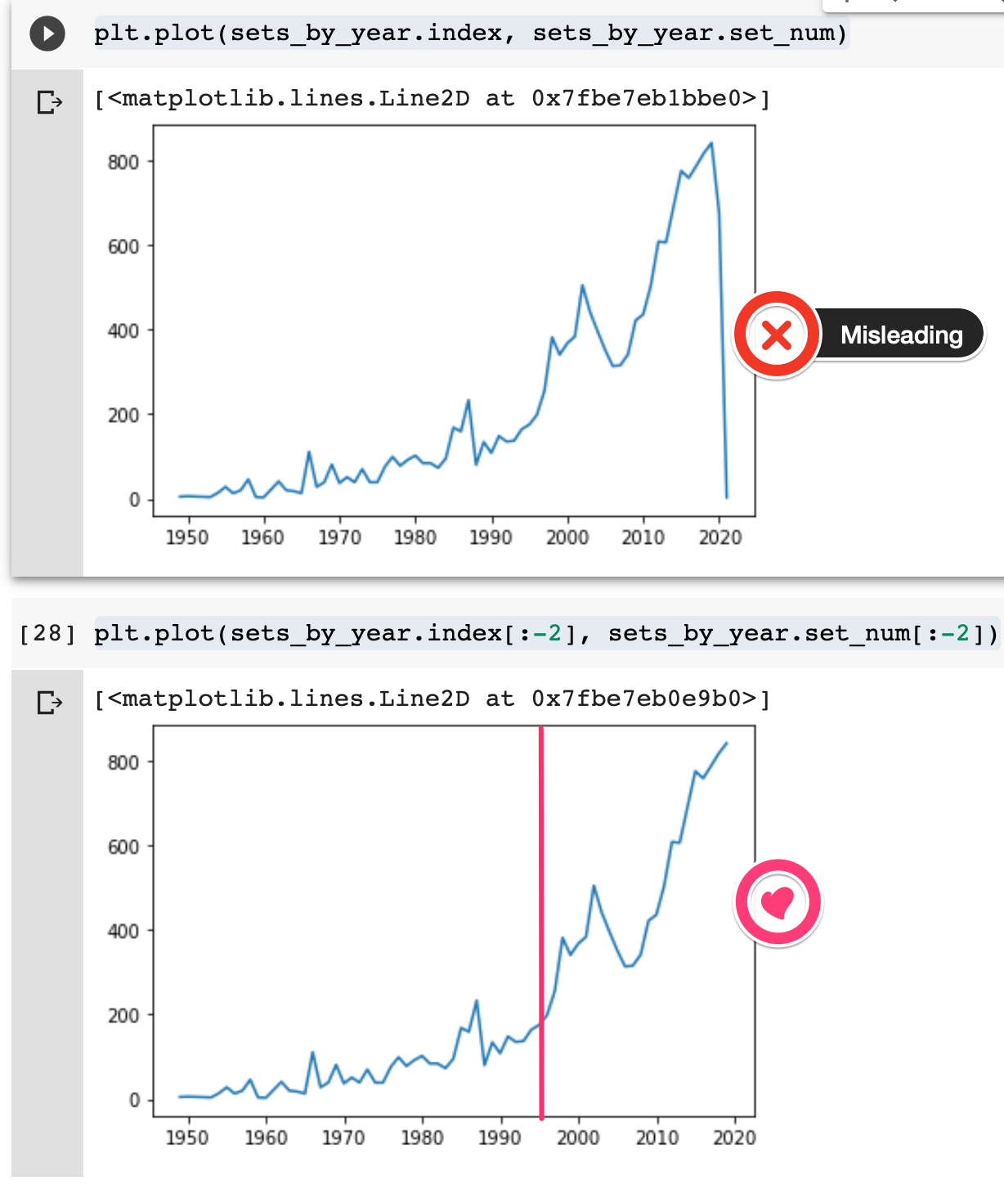
이를 matplotlib으로 시각화 할 수 있다. 단, 해당 데이터는 2020년 초기 데이터로 2020년 데이터를 제외해야한다.
슬라이싱 기법을 pandas 데이터프레임에도 사용할 수 있다.
# 최근 2년치 제외하기
plt.plot(sets_by_year.index[:-2], sets_by_year["set_num"][:-2])
plt.show()
연도별로 테마의 수를 알아보자.
groupby()와 agg() 함수를 사용해서 데이터를 요약할 수 있다.
agg()함수의 인자는 딕셔너리 형태라는 것을 기억해야한다.
themes_by_year = sets.groupby("year").agg({"theme_id":pd.Series.nunique})