오늘 알아볼 질문
많은 영화 예산이 박스오피스에서 더 많은 수익으로 이어지는가?
오늘 배울 내용
데이터 확인 및 전처리
먼저 데이터의 구성과 NaN 존재 여부, 중복값 확인 및 데이터의 유형을 확인한다.
df = pd.read_csv('cost_revenue_dirty.csv')
# 데이터 구성 확인print(df.shape)# (5391, 6)# NaN 존재 확인print(df.isna().values.any())# False# 중복값 확인print(df.duplicated().values.any())# False# 데이터 유형 확인print(df.info())
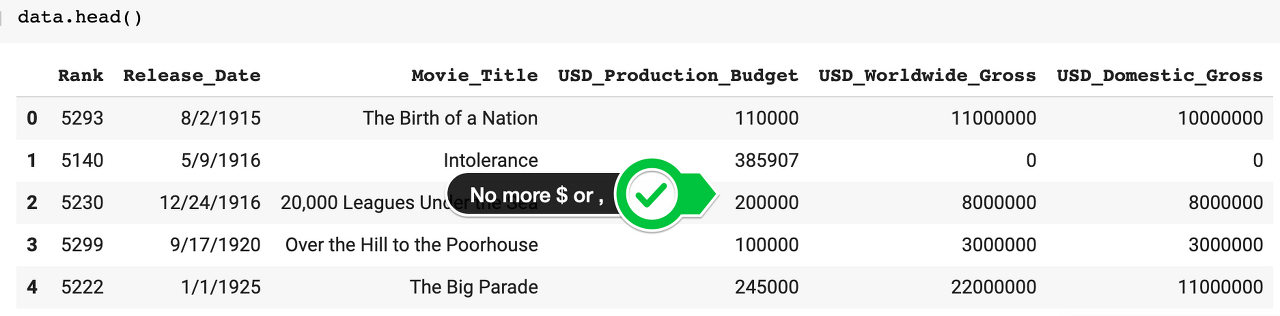
또한 금액의 경우 $ 표시와 , 표시가 있으므로 이를 제거하고 숫자 형식으로 변환한다.
# USD_Production_Budget / USD_Worldwide_Gross / USD_Domestic_Gross 숫자 형식으로 변환
chars_to_remove = [',', '$']
columns_to_clean = ['USD_Production_Budget',
'USD_Worldwide_Gross',
'USD_Domestic_Gross']
for col in columns_to_clean:
for char in chars_to_remove:
# replace를 사용하여 없애기
df[col] = df[col].astype(str).str.replace(char, "")
# 숫자 형식으로 데이터 변환
df[col] = pd.to_numeric(df[col])
Release_data를 Pandas Datetime 유형으로 변환한다.
# Release_Date Pandas Datetime 유형으로 변환하기df.Release_Date = pd.to_datetime(df.Release_Date)
모두 잘 바뀐것을 확인할 수 있다.
# Column Non-Null Count Dtype
--- ------ -------------- -----0 Rank 5391 non-null int64
1 Release_Date 5391 non-null datetime64[ns]
2 Movie_Title 5391 non-null object
3 USD_Production_Budget 5391 non-null int64
4 USD_Worldwide_Gross 5391 non-null int64
5 USD_Domestic_Gross 5391 non-null int64